
Analysis of 4,608 TED Talks: Part of Speech Tagging, Word Frequency, and Adherence to Zipf's Law
Using 4,608 TED Talks, we sought to investigate the distribution of words used across speaker categories and different parts of speech to test for alignment with the widely known mathematical form known as Zipf’s law.
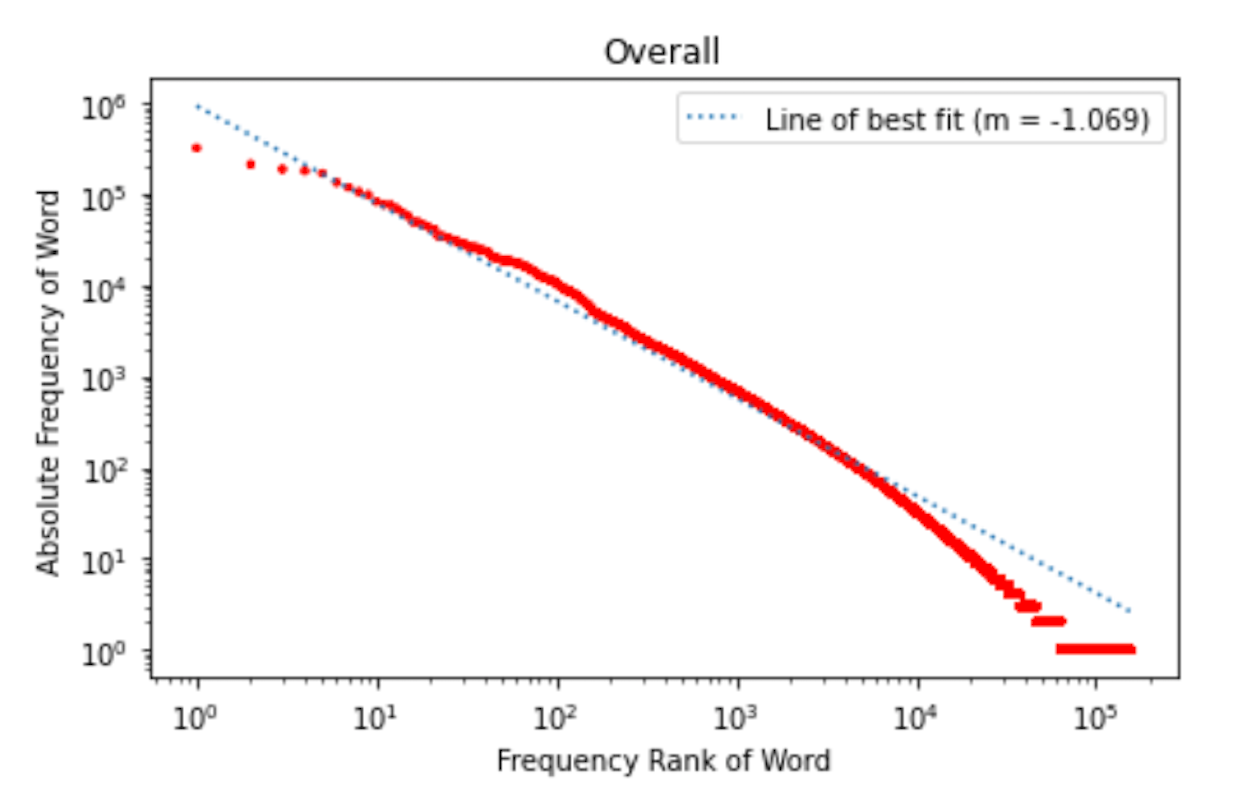
Introduction to Zipf's Law
Despite the complexity of human language, one incredibly simple mathematical framework known as Zipf’s law can be used to model language from all over the globe--even languages that have yet to be entirely decoded. The frequency distribution of words follows Zipf's law, and has been a key object of study in statistical linguistics for the past 70 years. It is of interest to further explore how the frequency of words relates to human comprehension of language, because Zipf’s law appears to convey a noteworthy relationship between frequency of word usage and word complexity.
Piantadosi's article on Zipf's word frequency law in natural language shows that Zipf’s law can be described as follows, where “r” corresponds to the frequency rank of a word, and f(r) is the frequency in a natural corpus (body of text). The most frequent word (r = 1) has a rank of 1 (frequency proportional to 1), while the second most frequent word (r = 2) has a frequency proportional to 1/2^a and so forth. In this equation, a ≈ 1.
f(r) ∝ 1/r^a
While Zipf’s law was originally defined with respect to language, it has since been used to describe all kinds of complex phenomena, ranging from the sizes of cities in a country, to the distribution and sizes of craters on the moon, to musical notes in our favorite songs, and beyond. Elucidating the nature of its occurrence has remained a significant challenge for researchers, and it is not well understood why or how such disparate sets of data follow the same fundamental law. Zipf's law resembles a power law relationship, and such distributions have been observed across a wide variety of complex systems.
To gain a better grasp of this concept and verify the English language’s adherence to Zipf’s law across subject domains, we identified a dataset comprising 4,608 TED Talk transcripts from Kaggle to test its alignment with Zipf’s law.
SpaCy is a free open-source library for Natural Language Processing in Python. We used SpaCy to identify and count words from different parts of speech to further test for Zipfian-like distributions.
Methodology:
- Clean up text transcripts (avoid irrelevant marks/punctuation).
- Count frequencies of words across all transcripts.
- Filter by speaker type and tag words (and clean up as needed).
- Analyze word frequencies in transcripts from top speaker and tag word categories to find the top words used.
- Use SpaCy to tag words of various parts of speech (verb, noun, adjectives, adverbs) and analyze the word frequencies in each category.
- Plot log-log plots for each analysis.
- Find slope of the line of best fit possible.
- Compare results with Zipf’s law and determine value for alpha (a).
Part of Speech Tagging With SpaCy
Import and Load
import spacy
nlp = spacy.load('en_core_web_sm')
Analyze the output
doc = nlp(transcript_text)
for token in doc:
if token.pos_ == "VERB":
word = token.text
Results:
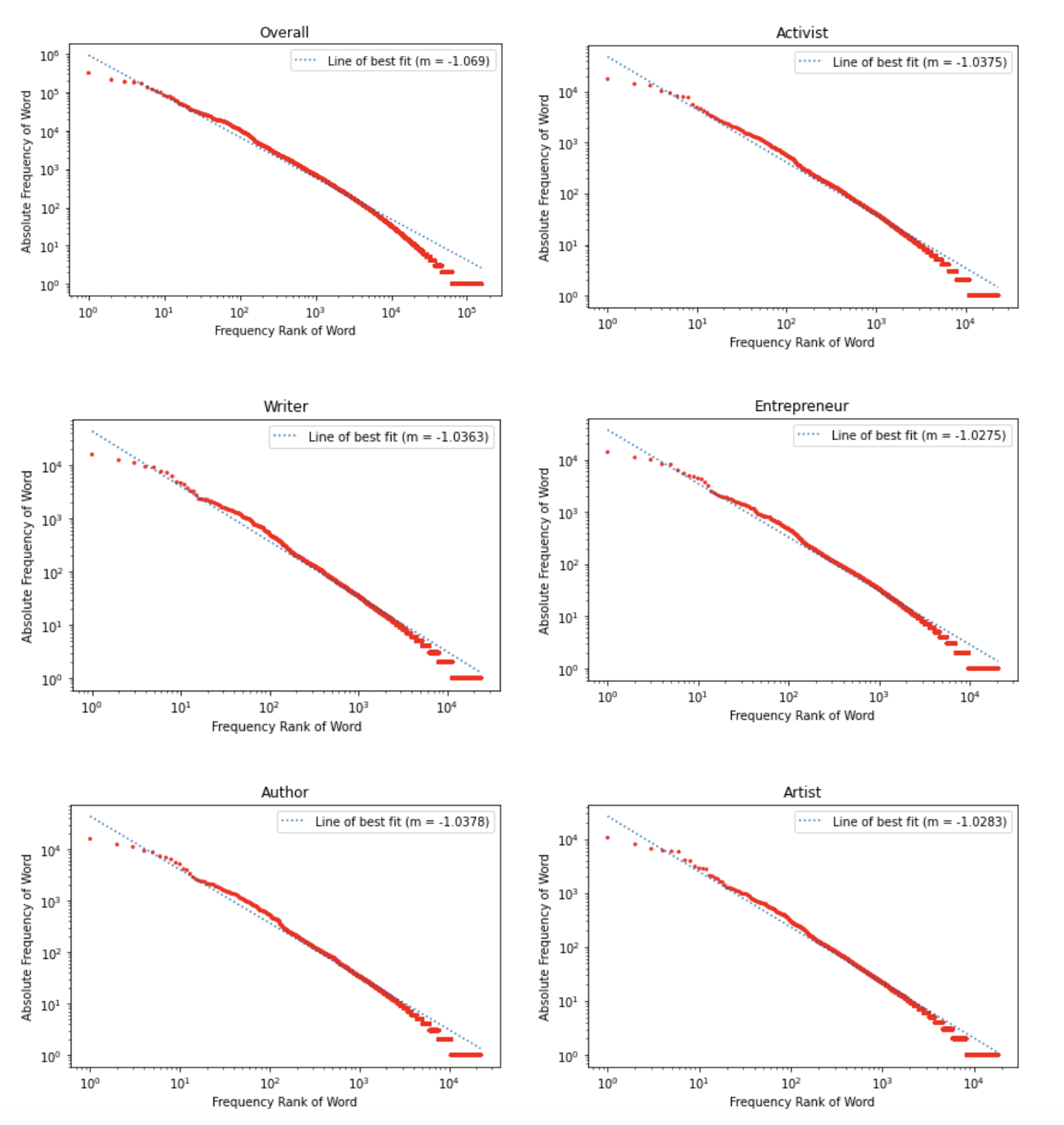
TED Talk Speaker Types (Top 5)
To further test for adherence to Zipf’s law across different subject domains, we parsed out the TED Talks by speaker description to identify the most common types of individual speakers. The top five speaker type categories are as follows: (1) activist, (2) writer, (3) entrepreneur, (4) author, (5) artist. The overall frequency rank across speaker categories is shown in the upper left hand cell for comparison. The differences between categories is unremarkable.

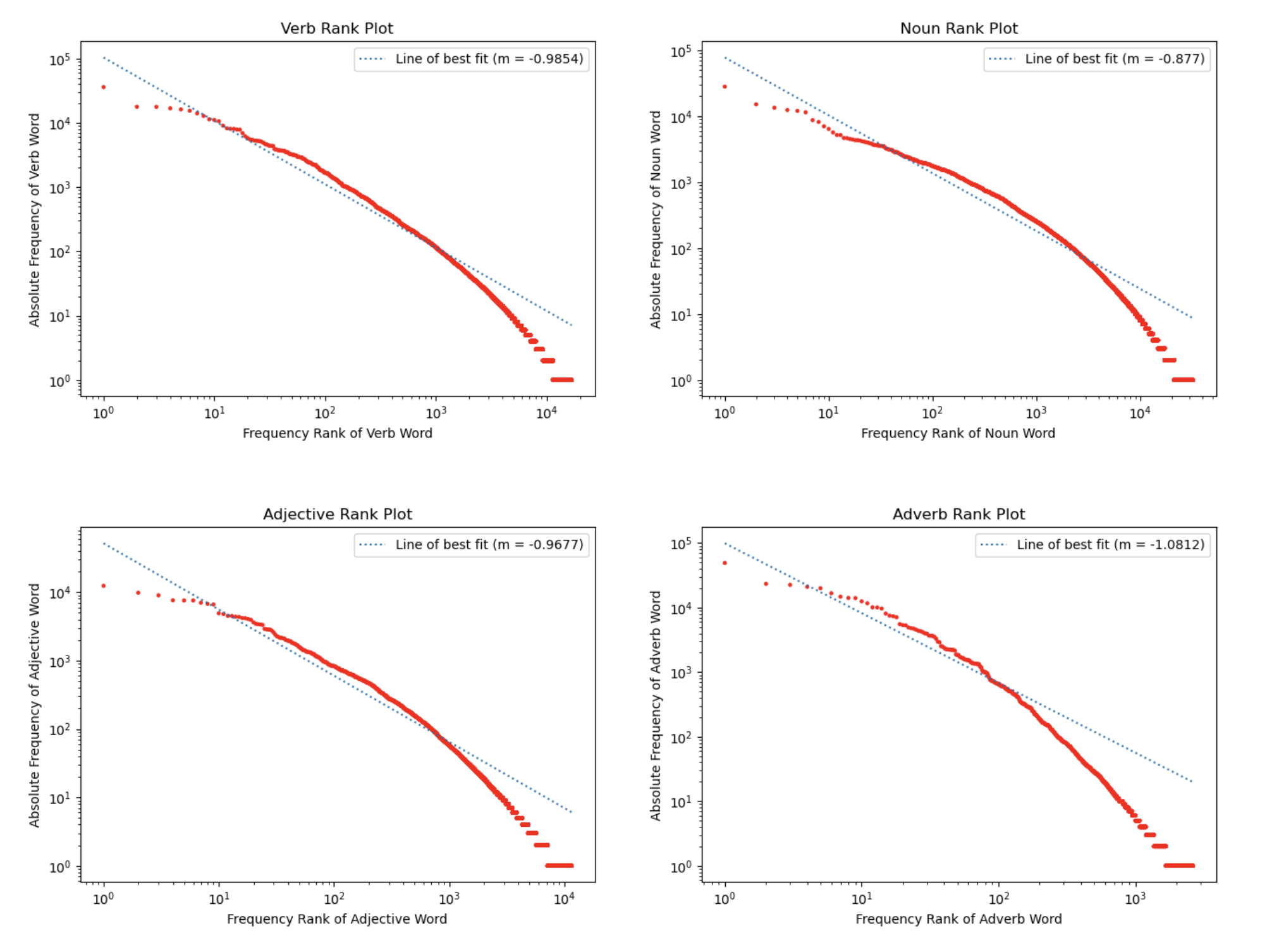
TED Talk Parts of Speech Analysis (Verbs, Nouns, Adjectives, and Adverbs)
To determine if the frequency rank distribution of words in different parts of speech categories adhere to Zipf’s law, we used a Natural Language Processing library known as SpaCy to assist in our analysis. Words across all TED Talks were fed into a function defining the NLP library, where all tokens in the transcripts (i.e. all words, punctuation marks, and any other variables present) could be tagged with their respective parts of speech. A second criteria determined whether each token was indeed a word, and if so, all capitalizations were removed and words were sifted into the following four different parts of speech categories: (1) verbs, (2) nouns, (3) adjectives, and (4) adverbs.

Conclusion
Using a compilation of 4,608 TED Talks, we sought to investigate the alignment of transcripts with the widely known mathematical form known as Zipf’s law. First, words from all available TED Talks were counted, and words were ranked based on their respective frequencies in the corpus. This distribution does indeed appear to follow a power law distribution, like that of Zipf’s law. To further explore the transcripts alignment with Zipf’s law, we tested the alignment across speaker description categories, as well as that of different parts of speech present across all talks. We identified the top five speaker categories as (1) Activist, (2) Writer, (3) Entrepreneur, (4) Author, and (5) Artist. Parts of speech used were (1) Verbs, (2) Adjectives, (3) Nouns, and (4) Adverbs.
We did observe a power law relationship for overall words across TED Talk transcripts, the speaker types. We observe that the overall value for alpha is around 1.07, with alpha for speaker types ranging from 1.02-1.04 and parts of speech 0.8-1.08, respectively.
It appears as though different parts of speech may behave differently when compared to the overall corpus, which may suggest something unique about the way we use various parts of speech. Further investigation into the topic must be performed to uncover the meaning behind this finding. Nonetheless, this project can be seen as a success--TED Talk transcripts do indeed align with Zipf's law.